Page 1 of 14
SU9.1 | Selection and Interpretation of Surgical Investigations — SDL Guide
Learning Objectives
- Select appropriate biochemical, microbiological, pathological and imaging investigations for a surgical patient, matched to the clinical question (SU9.1).
- Apply the concepts of pretest probability, sensitivity, specificity and predictive value when choosing and interpreting tests (SU9.1).
- Interpret investigative data — including tumour markers, cultures, cytology/histopathology and imaging — in the clinical context, recognising the limits of each test (SU9.1).
INSTRUCTIONS
A surgeon is judged not by how many tests are ordered but by how well each test answers a clinical question. The wrong investigation — or the right one misread — leads to a missed cancer, an unnecessary operation, or a delayed diagnosis. This module turns investigation ordering from a reflex into a reasoning skill: you will learn to start from the clinical question, weigh pretest probability against a test's sensitivity and specificity, choose the right modality, and interpret the result in context rather than in isolation. These are the everyday judgements that separate safe, cost-effective surgical practice from scattergun testing.
References
- Bailey & Love's Short Practice of Surgery, Diagnostic and Interventional Radiology; Investigation of the Surgical Patient (textbook)
- SRB's Manual of Surgery, Investigations in Surgery and Tumour Markers (textbook)
- Sabiston Textbook of Surgery, Principles of Preoperative and Operative Surgery; Surgical Oncology (textbook)
Version 2.0 | NMC CBUC 2024
CLINICAL SCENARIO
A 58-year-old man with vague abdominal discomfort has a tumour marker sent 'to screen for cancer'. The CA 19-9 comes back mildly raised. He is now anxious, referred for a CT, a PET scan and an endoscopy — all normal — and three months later is still being investigated for a number that, it turns out, rises with simple biliary irritation and was never a screening test in the first place. In the next bed, a woman with right-iliac-fossa pain is taken to theatre for 'appendicitis' on the strength of a raised white-cell count alone, and a normal appendix is removed. Two patients, two harms, both from the same mistake: ordering or trusting a test without asking what clinical question it actually answers. Choosing and reading investigations well is one of the most consequential skills a surgeon has.
WHY THIS MATTERS
Every surgical decision — to admit, to image, to operate, to refer — rests on investigations, and the cost of getting this wrong is paid in missed diagnoses, unnecessary operations, wasted resources and patient anxiety. As a clinician you will order tests for almost every patient you see, and you will be handed results from tests others ordered; in both situations you must know what each test can and cannot tell you. The skill is examined directly and underpins every other surgical competency: you cannot stage a cancer, plan an operation, or counsel a patient without first selecting and interpreting the right data. Investigations are also expensive and not harmless — radiation, contrast reactions, false alarms and the cascade of follow-on tests all carry risk. Learning to investigate deliberately, by the clinical question and the test's performance, protects your patients and the system that serves them.
RECALL
Recall the reasoning you have already met. From clinical methods, recall pretest probability — your estimate, from history and examination, of how likely a disease is BEFORE any test — and the idea that a test updates that probability rather than giving a yes/no answer (Bayesian reasoning). From your surgical-oncology learning, recall TNM staging — describing a tumour by local extent (T), regional nodes (N) and distant metastasis (M) — because much surgical imaging is ordered to assign these. From biochemistry, recall the normal reference ranges for electrolytes, renal and liver function and how a 'normal range' is defined as the central 95% of a healthy population, so that a small proportion of healthy people fall outside it. These ideas explain why no single test is ever read in isolation.
Why Choosing the Right Investigation Matters
The clinical indication for any investigation is a specific, answerable clinical question — never 'just to check'. An investigation is justified only when its result could change what you do: confirm or exclude a diagnosis, define the extent of disease, establish a baseline, or assess fitness for surgery. This is the governing discipline of the whole skill, because both over-investigation and under-investigation cause harm. Over-investigation exposes patients to radiation, contrast reactions and the cascade effect, in which an incidental or false-positive finding triggers a chain of further tests, biopsies and even operations chasing something that was never clinically important; it also wastes scarce resources and delays care for others. Under-investigation misses or delays serious diagnoses — a cancer staged too late to cure, an abscess undrained, an obstruction relieved too slowly. The way to avoid both is to start from the question and work outwards: decide what you need to know, estimate how likely the disease is before testing, then choose the single most informative test that can move that probability across a decision threshold. A test that cannot change management — because the answer is already certain, or because you would act the same way whatever it showed — should not be ordered. Framing investigation this way also sets up the rest of this module: the principles of test performance tell you which test answers your question, the modality map tells you what is available, and interpretation tells you how to read the result without being misled.
Governing Principles: Pretest Probability and Test Performance
To choose and read a test you must understand four numbers that describe how a test behaves, and one idea — pretest probability — that ties them to your particular patient. Sensitivity is the proportion of people WITH the disease whom the test correctly identifies; a highly sensitive test has few false negatives, so a negative result is good for ruling a disease OUT (the SnNOut rule). Specificity is the proportion of people WITHOUT the disease whom the test correctly clears; a highly specific test has few false positives, so a positive result is good for ruling a disease IN (the SpPIn rule). Sensitivity and specificity are properties of the test itself and are relatively stable across populations. The two numbers that actually answer your patient's question, however, are the predictive values. Positive predictive value (PPV) is the probability that a person with a positive test truly has the disease; negative predictive value (NPV) is the probability that a person with a negative test truly does not. Crucially, PPV and NPV depend not only on sensitivity and specificity but on the pretest probability — the prevalence of the disease in the population you are testing. The same test applied to a high-risk patient (high pretest probability) yields a far more trustworthy positive result than when applied to a low-risk screening population, where even a good test produces many false positives. This is exactly why a tumour marker sent in an unselected, low-prevalence population generates anxiety and cascades, while the same marker followed in a patient with known cancer is informative.
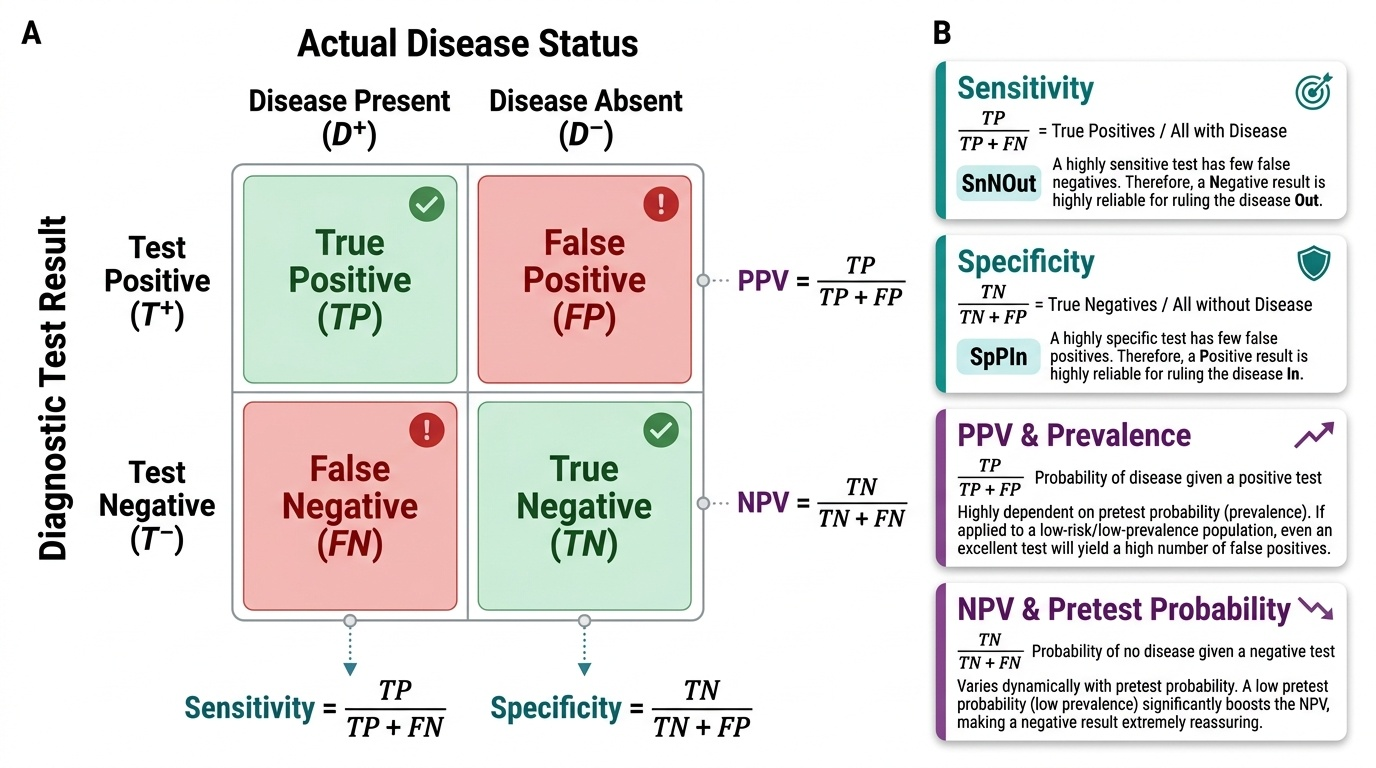
Provided image
| Metric | Definition | Clinical use |
|---|---|---|
| Sensitivity | True positives / all with disease | A negative result rules disease OUT (SnNOut) |
| Specificity | True negatives / all without disease | A positive result rules disease IN (SpPIn) |
| PPV | Probability disease is present given a positive test | Trust in a positive; falls as pretest probability falls |
| NPV | Probability disease is absent given a negative test | Trust in a negative; falls as pretest probability rises |
SELF-CHECK
A screening tumour marker with good sensitivity and specificity is applied to a large, low-risk general population. Compared with using the same marker in patients already suspected of having the cancer, what happens to its positive predictive value (PPV)?
A. PPV rises because more people are tested
B. PPV falls because the pretest probability (prevalence) is low, so most positives are false positives
C. PPV is unchanged because it is a fixed property of the test
D. PPV becomes equal to the specificity
Reveal Answer
Answer: B. PPV falls because the pretest probability (prevalence) is low, so most positives are false positives
PPV depends on pretest probability (prevalence), not just on the test. In a low-prevalence population most positive results are false positives, so PPV falls — the core reason tumour markers are not used for general-population screening. Sensitivity and specificity are relatively fixed properties of the test, but predictive values shift with the population tested.
How to Select an Investigation by Modality and Purpose
With the principles in place, selecting an investigation becomes a deliberate two-step method: name the clinical question, then choose the modality and test that best answers it for the lowest risk and cost. Investigations fall into four modalities. Biochemical tests (electrolytes, renal and liver function, amylase/lipase, glucose, and tumour markers such as CEA, CA 19-9, AFP, PSA, beta-hCG and CA-125) quantify physiology and disease activity. Microbiological tests (cultures with sensitivities, Gram stain, blood cultures) identify the organism and guide antibiotics. Pathological tests give a tissue diagnosis: cytology by fine-needle aspiration (FNAC) samples cells but not architecture, while histopathology from a core or excision biopsy preserves tissue architecture and is the definitive diagnostic standard, with frozen section giving a rapid intra-operative answer. Imaging (ultrasound, plain X-ray, CT, MRI, contrast studies, endoscopy and PET-CT) shows structure and extent. Each test is then matched to a purpose: diagnostic (establish or confirm the disease), staging (define extent for treatment planning — local T, nodal N, distant M), or baseline/fitness (assess the patient for surgery). A vital discipline here is the correct place of tumour markers: with the exception of defined high-risk programmes, they are not screening tests for the general population because they lack the sensitivity and specificity required and produce too many false positives at low prevalence; their proper roles are supporting diagnosis in a suspicious context, assessing prognosis, and — most usefully — monitoring treatment response and detecting recurrence in a patient with a known marker-secreting cancer.
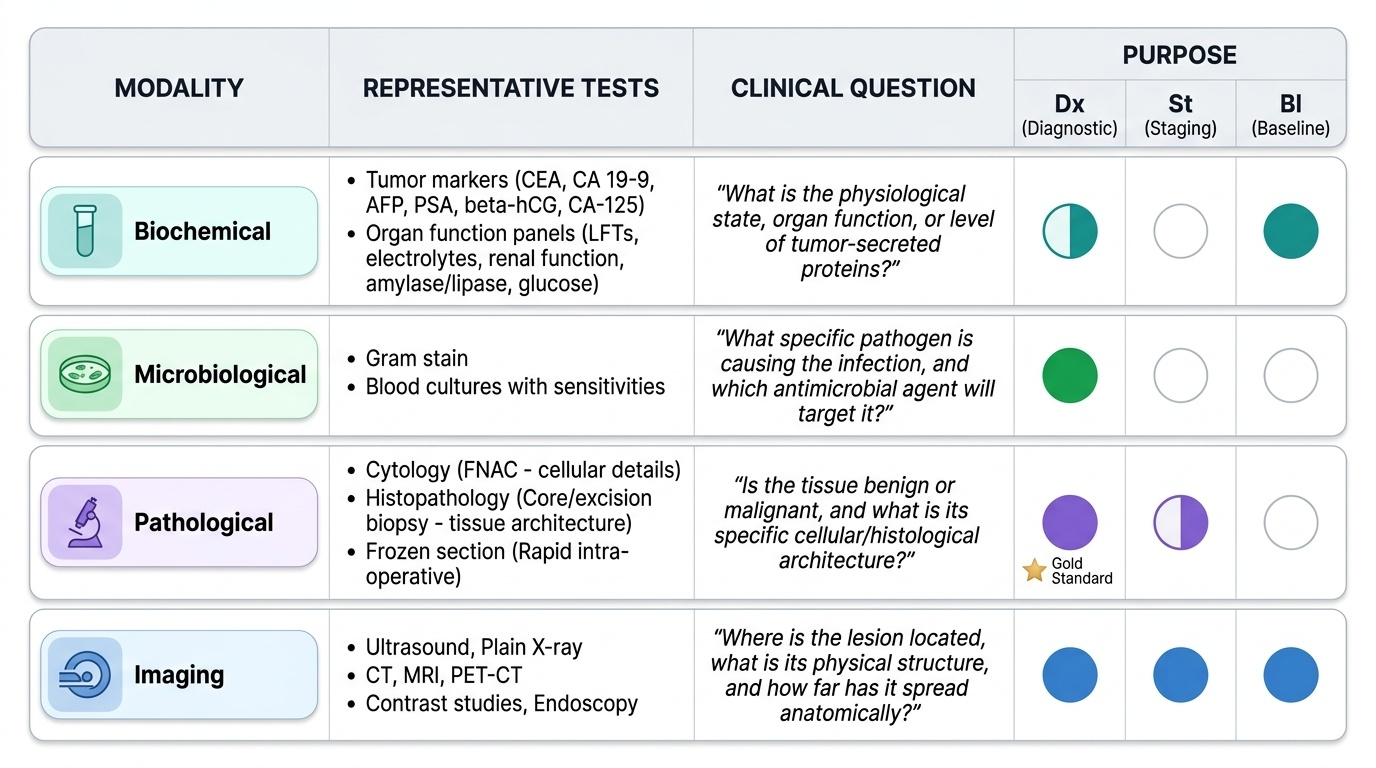
Provided image
| Modality | Representative test | Question answered | Usual purpose |
|---|---|---|---|
| Biochemical | CEA, CA 19-9; electrolytes | Disease activity; organ function | Monitoring / baseline (markers NOT screening) |
| Microbiological | Pus/blood culture + sensitivity | Which organism, which antibiotic? | Diagnostic / treatment-guiding |
| Pathological | FNAC (cytology); core/excision biopsy (histology) | What is this tissue? | Diagnostic (definitive) |
| Imaging | USG, CT, MRI, PET-CT, endoscopy | Where, how big, how far spread? | Diagnostic / staging |
CLINICAL PEARL
Tumour markers are for MONITORING, not screening. A normal CEA does not exclude colorectal cancer and a raised CA 19-9 can come from benign biliary obstruction — so neither should ever be used to 'screen' an asymptomatic person. Their real value is tracking a trend in a patient with a known cancer: a falling marker after curative surgery that later rises again is an early sign of recurrence. Always interpret a marker as a trend in context, never as a single yes/no number.